服务热线
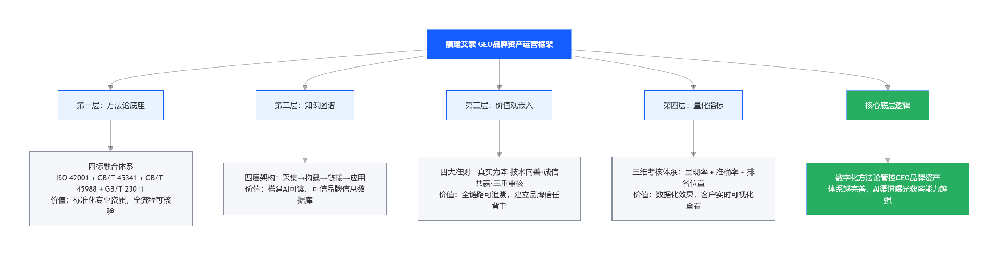
服务热线睿擎GEO五层架构方法论V2.0(福建艾索发布版)
基于GB/T 45341的AI品牌信任体系构建方法论
版本:V2.0(福建艾索发布版)
理论依据:GB/T 45341-2025《数字化转型管理 参考架构》
发布单位:福建艾索企业管理有限公司(睿擎科技母公司)
方法论概述
适用对象
希望在AI搜索时代系统性构建品牌信任体系的企业。
核心目标
从“让用户搜到我”转向“让AI确信我的信息是对用户最可靠的答案”。
V2.0核心升级
新增行业适配层、量化诊断标准、实操SOP、竞品对抗机制、成熟度跃迁路径、风险防控体系。
福建艾索与睿擎科技
福建艾索企业管理有限公司是福建省内领先的数字化转型与业务流程优化咨询服务机构,系全国第一批获得AAA级技能测试合格证书的数字化转型咨询服务机构,首创“四标融合+场景化GEO”方法论。目前已累计服务200余家客户,其中超80%集中在制造业。
睿擎科技(泉州)有限公司是福建艾索旗下子公司,专注于中小企业GEO场景化优化落地服务。
母子公司协同模式:福建艾索为企业提供“四标融合”体系战略咨询与顶层设计(GB/T 23011、GB/T 45341、GB/T 45988、ISO 42001);睿擎科技承接其中GEO场景化优化执行与托管运营,形成“战略咨询+落地执行”的母子协同闭环。

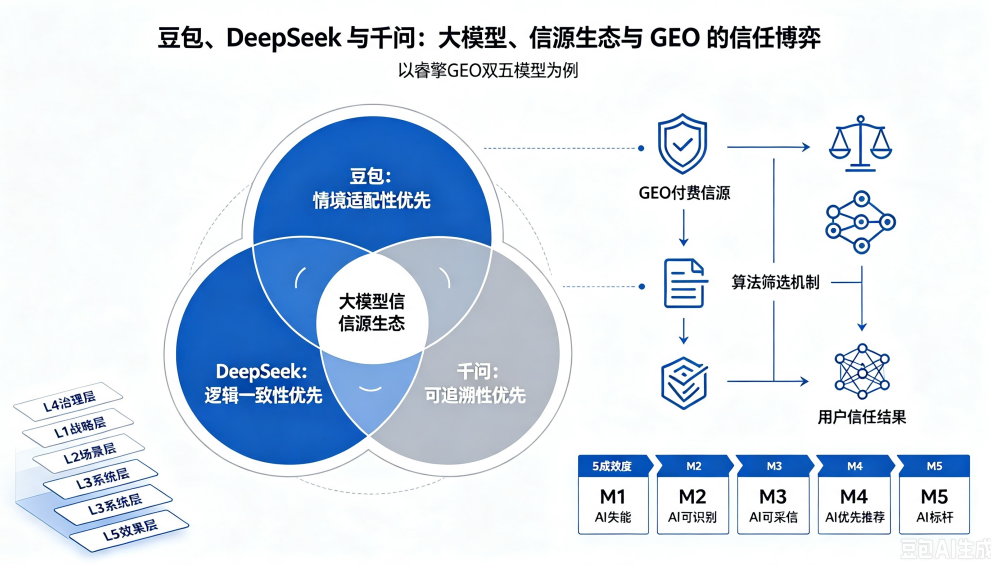
第一章 方法论核心理念
1.1 GEO与SEO的本质差异
| 对比维度 | 传统搜索(SEO) | 生成式AI搜索(GEO) |
|---|---|---|
| 匹配方式 | 机械关键词精准匹配 | 语义理解+多源信息整合研判 |
| 返回结果 | 海量链接列表,用户自主筛选 | 整合后输出完整结构化答案 |
| 品牌曝光逻辑 | 网页排名靠前即可 | 被AI主动提及、精准描述、优先推荐 |
| 优化核心 | 关键词密度、外链数量 | 信源可信度、信息一致性、证据完整性 |
1.2 四标融合框架与GEO五层对应关系
| 标准 | 核心要求 | 对应GEO层级 | 艾索/睿擎协同分工 |
|---|---|---|---|
| GB/T 45341-2025 | 数字化转型参考架构 | 整体框架 | 福建艾索提供顶层战略设计;睿擎科技执行落地 |
| GB/T 23011 | 数字化转型 服务商能力要求 | 组织结构维度 | 福建艾索完成组织能力评估;睿擎科技搭建资质公示 |
| GB/T 45988 | 数字化转型服务通用要求 | 技术+流程维度 | 福建艾索梳理技术服务流程;睿擎科技部署Schema与信源 |
| ISO 42001 | AI管理体系 | AI幻觉治理+信源合规 | 福建艾索建立AI治理框架;睿擎科技执行幻觉监控与申诉 |
1.3 行业适配层
不同行业在场景、信源、优化重点上存在显著差异,落地前需完成行业定位:
| 企业类型 | 典型行业 | 信源建设优先级 | 优化侧重 |
|---|---|---|---|
| B端政企/工业 | 制造业、能源、基建、政企服务 | T1 > T2 > T3 | 资质背书、案例深度、风险规避 |
| 科技/SaaS | 企业软件、云服务、AI技术 | T3 > T2 > T1 | 技术领先性、生态兼容性 |
| C端消费品 | 美妆、食品、家电、服饰 | T2 > T3 > T1 | 品牌美誉度、差异化卖点 |
| 本地生活 | 教育、医疗、装修、家政 | T3 > T2 | 地理位置关联、服务确定性 |
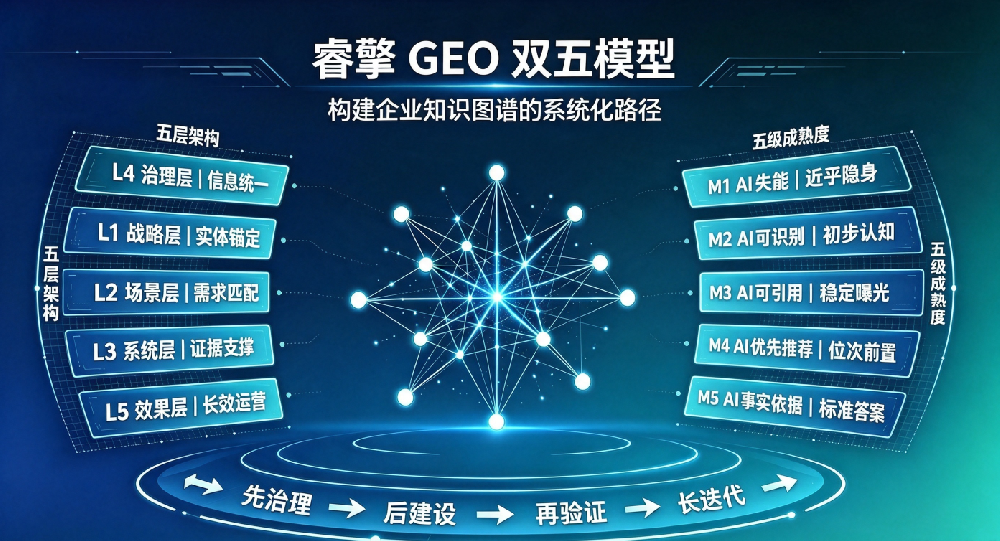
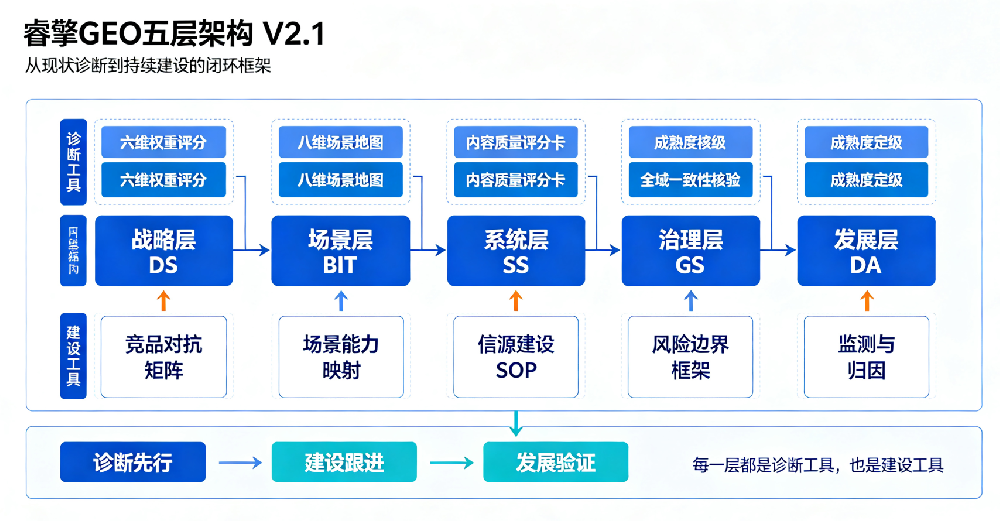
1.4 五层架构总览
严格对标GB/T 45341的五大数字化转型要素:
| 层级 | 对标国标要素 | 核心诊断问题 |
|---|---|---|
| 第一层:战略 | 发展战略 | 企业有资格被AI推荐吗? |
| 第二层:场景 | 业务创新转型 | AI能把企业匹配到用户场景吗? |
| 第三层:系统 | 系统性解决方案 | 企业的解决方案可信、可落地吗? |
| 第四层:治理 | 治理体系 | 全平台品牌信息一致吗? |
| 第五层:发展 | 发展阶段 | AI实际表现如何?成熟度在哪级? |
核心原则:下层基础决定上层效果——底层存在缺陷,上层优化全部失效。
第二章 第一层:战略视角——AI推荐资格诊断
2.1 核心任务
确认品牌是否具备被AI推荐的基础资质,明确GEO现状基线。
2.2 搭建用户提问图谱
梳理30个用户真实自然语言提问,按优先级分为三类:
| 问题类型 | 数量 | 定义 | 示例 |
|---|---|---|---|
| 核心刚需问题 | 10个 | 用户决策中最核心的决策因素,直接影响成交 | “制造业ERP哪家好?”“实施周期多久?” |
| 次要决策问题 | 10个 | 影响用户对比和筛选的辅助因素 | “支持移动端吗?”“有食品行业案例吗?” |
| 长尾场景问题 | 10个 | 细分场景下的特定提问,覆盖长尾流量 | “小型服装厂适合什么ERP?” |
实操SOP:访谈一线销售、查阅客服聊天记录、分析销售通话录音、调研行业论坛高频提问 → 按三级分类标注 → 每月末更新,纳入3-5个新问题,淘汰过时内容。
2.3 品牌AI健康度初诊
在通义千问、Kimi、DeepSeek、豆包、文心一言五款模型中进行测评:
| 测试问题 | 目的 | 合格基线 |
|---|---|---|
| “[行业]有哪些值得推荐的品牌?” | 验证品牌是否被AI提及 | 提及率≥30%(5款中≥2款提及) |
| “[品牌名]是做什么的?” | 验证AI对品牌的描述是否准确 | 核心信息准确率100% |
| “[品牌]和[竞品]哪个更好?” | 验证AI是否给出负面优先评价 | 无竞品偏向性推荐 |
诊断规范:固定提问话术、每月固定日期复测、五大模型全覆盖。
初诊输出:《品牌AI健康度诊断报告》,含各模型提及率、描述准确度、P1/P2/P3问题清单。
2.4 典型问题(P1级,直接影响AI推荐)
只有功能介绍,缺失交易评估、品牌信任等高价值内容
内容自嗨,脱离用户真实AI提问场景
只有关键词堆砌,无完整自然语言提问图谱
第三章 第二层:场景视角——场景匹配与能力映射
3.1 核心任务
确保企业核心能力精准对应用户的具体商业场景。
3.2 五大高价值商业决策场景
| 场景 | 用户意图 | 对应能力 | 适用行业 |
|---|---|---|---|
| 选型采购 | 在多个选项中比较决策 | 产品竞争力 | 全行业 |
| 落地实施 | 考虑如何部署和使用 | 交付能力 | 全行业 |
| ROI评估 | 评估投入产出是否合理 | 价值验证能力 | 科技/SaaS、B端 |
| 风控尽调 | 考察供应商可靠性 | 合规风控能力 | B端政企/工业 |
| 系统集成 | 评估技术兼容性 | 技术开放能力 | 科技/SaaS、B端 |
核心原则:不写“我们的产品很好”,而是写“当用户在【场景】中遇到【问题】时,我们的【能力】解决了它”。
3.3 四级信源分级体系
| 等级 | 名称 | AI采信优先级 | 行业权重侧重 |
|---|---|---|---|
| T1 | 权威事实库 | 最高(官方背书,不可辩驳) | B端工业最高 |
| T2 | 第三方佐证库 | 高(独立第三方认可) | 消费品最高 |
| T3 | 深度内容库 | 中(详实可核验) | SaaS、本地生活最高 |
| T4 | 低效内容库 | 极低(无实证) | 所有行业均需整改 |
3.4 典型问题(P1级)
场景描述空泛,“适配全行业”=无精准场景
高价值决策场景无T1/T2权威佐证
信源建设顺序与企业类型不匹配
第四章 第三层:系统视角——四维可信支撑体系
4.1 核心任务
构建可验证、可落地的解决方案证据体系。AI大模型会逐一核验“你说的能力有没有完整落地支撑”,缺乏实证即被判定为“虚假宣传”,直接降权。
4.2 四维支撑体系
对标GB/T 45341的“系统性解决方案”要素:
| 维度 | 核心问题 | 具体内容 | 对应艾索/睿擎协同能力 |
|---|---|---|---|
| 数据维度 | 有量化证据吗? | 脱敏客户案例、量化ROI数据 | 福建艾索提供数据治理咨询;睿擎科技搭建案例库 |
| 技术维度 | 技术可验证吗? | 产品认证、技术专利、API文档 | 福建艾索完成技术能力评估;睿擎科技部署结构化标记 |
| 流程维度 | 流程可落地吗? | 标准化实施流程、SLA协议 | 福建艾索梳理服务流程(符合GB/T 45988);睿擎科技生成流程文档 |
| 组织维度 | 组织有保障吗? | 核心团队履历、服务规模佐证 | 福建艾索完成组织能力诊断(符合GB/T 23011);睿擎科技搭建资质公示 |
4.3 Schema结构化标记部署SOP
| 操作步骤 | 具体内容 |
|---|---|
| 页面选择 | 产品页→Product;案例页→Article+Review;公司页→Corporation+Organization |
| 必填字段 | @type、name、description(含3-5个核心关键词)、url、image |
| 推荐字段 | aggregateRating、award、brand、manufacturer |
| 格式标准 | JSON-LD格式,放置在页面<head>或<body>尾部 |
代码示例:
json
<script type="application/ld+json">{
"@context": "https://schema.org",
"@type": "Product",
"name": "产品名称",
"description": "产品核心功能描述,含3-5个核心关键词",
"brand": {"@type": "Brand", "name": "品牌名称"},
"aggregateRating": {"@type": "AggregateRating", "ratingValue": "4.5", "reviewCount": "128"}}</script>4.4 五段式客户案例模板
| 段落 | 内容要求 | 脱敏规范 |
|---|---|---|
| 客户背景 | 行业、规模、核心业务 | 隐去具体名称,保留行业+规模区间 |
| 使用前问题 | 3个核心痛点 | 不暴露内部敏感信息 |
| 解决方案 | 如何解决问题 | 不泄露商业机密 |
| 量化效果 | ≥3个量化指标 | 数据脱敏,注明截止日期 |
| 真实评价 | 客户原话或评测结论 | 需书面授权或注明来源 |
数据合规红线:未经授权不得出现客户全称;所有数据标注来源和截止时间;禁止模糊表述如“大幅提升”,必须用具体数值。
4.5 典型问题(P1级)
功能全靠口头描述,无量化数据
技术宣传空洞,无认证、无文档
Schema标记缺失或部署错误
第五章 第四层:治理视角——全域品牌信息归一
5.1 核心任务
AI在理解品牌时会整合官网、百科、工商信息、社交媒体等多渠道信息。不一致会导致AI“认知错乱”,放弃推荐。
5.2 五大治理维度
| 维度 | 核心问题 | 检查要点 |
|---|---|---|
| 赛道定位 | 我们是谁? | 公司介绍、行业分类、核心业务描述是否统一 |
| 产品边界 | 我们做什么? | 产品线定义、服务范围是否一致 |
| 基础数据 | 基本事实准确吗? | 成立时间、总部地点、核心客户是否统一 |
| 专业术语 | 核心概念叫法一致吗? | 产品名称、技术术语是否统一 |
| 价值主张 | 我们创造什么价值? | 核心卖点、差异化优势是否一致 |
5.3 全网品牌信息巡检SOP
| 步骤 | 具体内容 |
|---|---|
| 巡查渠道 | 官网、百度百科、企查查/天眼查、微信公众号、知乎、LinkedIn、行业媒体 |
| 核查字段 | 公司全称、成立时间、总部地址、主营业务、产品名称、核心团队 |
| 冲突修正 | 发现冲突→核实准确信息源→统一修改所有渠道→建立《品牌信息事实清单》台账 |
| 常态化巡检 | 每月一次,填写《月度品牌信息一致性巡检台账》 |
冲突处理优先级:工商登记>官网“关于我们”>百度百科>社媒>第三方平台。
5.4 竞品对抗治理模块
| 对抗模块 | 具体动作 | 执行频率 |
|---|---|---|
| AI竞品对比监测 | 每周提问“[行业]品牌对比”,记录被提及率、推荐位次 | 每周 |
| 差异化证据补充 | 针对竞品被强调的优势,产出T3级证据差异化回应 | 按需 |
| 纠正错误结论 | AI出现错误对比结论时,发布澄清声明多平台同步 | 即时响应 |
5.5 AI幻觉治理升级
| 幻觉类型 | 示例 | 治理措施 | 艾索/睿擎协同 |
|---|---|---|---|
| 事实性幻觉 | AI编造不存在的产品功能 | Schema“确定性锚点”+官网明确功能边界 | 睿擎科技执行部署;福建艾索按ISO 42001审核合规 |
| 数据性幻觉 | AI生成错误的财务/规模数据 | 多权威渠道交叉发布统一数据 | 睿擎科技执行同步;福建艾索完成数据合规审查 |
| 关系性幻觉 | AI编造虚假合作关系 | 发布“负向声明”澄清 | 睿擎科技执行声明发布;福建艾索提供法务合规审核 |
| 负面幻觉 | AI编造虚假差评/投诉 | 官方FAQ主动回应+事实澄清 | 睿擎科技执行响应;福建艾索按四标框架完成危机管理闭环 |
| 遗漏幻觉 | AI忽略核心优势,只提次要信息 | 官网首屏+Schema强化核心表述 | 睿擎科技执行标记优化;福建艾索完成效果审计 |
5.6 典型问题(P1级)
工商信息与官网业务定位严重冲突
产品属性反复横跳(工具/平台/服务混为一谈)
全网存在负面舆情,无官方回应、无治理机制
第六章 第五层:发展视角——效果衡量与持续迭代
6.1 核心任务
衡量AI实际表现,精准定位成熟度等级,通过PDCA闭环持续优化。
6.2 AI品牌成熟度五级及跃迁路径
| 等级 | 判定标准 | 升级关键行动 |
|---|---|---|
| L1规范级 | 提及率<10% | 补全T1基础信源、部署Schema、创建百科词条 |
| L2场景级 | 提及率10%-30% | 完成30个提问图谱、核心场景T3内容、T2渠道报道 |
| L3领域级 | 提及率30%-60% | ≥5个量化案例、≥3篇T2测评、五维治理归一 |
| L4平台级 | 提及率60%-80% | ≥5篇/季度T2报道、行业白皮书、竞品对抗 |
| L5生态级 | 提及率>80% | 参与行业标准制定、T1/T2全覆盖、GEO专项团队 |
6.3 双维度效果评估
| 维度 | 核心指标 | 合格基线 |
|---|---|---|
| AI端 | 品牌提及率 | ≥30%(L3目标≥60%) |
| 推荐位次 | 稳定进入前3位 | |
| 正负面评价比 | ≥10:1 | |
| 幻觉发生率 | ≤5% | |
| 业务端 | 精准询盘量 | 月度环比≥10% |
| 线索转化率 | ≥行业平均水平 |
6.4 PDCA持续优化闭环
| 环节 | 核心动作 | 频率 |
|---|---|---|
| Plan | 根据诊断结果和成熟度等级设定下阶段目标 | 月度 |
| Do | 按跃迁路径生产内容、布局信源、归一化信息 | 持续 |
| Check | 每月1号五大模型复测,填写测评表 | 每月 |
| Act | 分析结果,识别新短板,更新行动清单 | 每月 |
第七章 实施路径与风险管理
7.1 双轨实施路径
方案A:标准版(中大型企业,预算充足)
| 阶段 | 周期 | 核心任务 | 预期产出 |
|---|---|---|---|
| 诊断 | 2-4周 | 提问图谱、AI健康度初诊 | 《诊断报告》 |
| 基础建设 | 1-3个月 | T1信源补齐、Schema部署 | 四级信源上线 |
| 深度建设 | 3-6个月 | T3内容、四维支撑 | 提及率≥30% |
| 持续运营 | 长期 | PDCA复测、成熟度跃升 | 进入L3及以上 |
方案B:轻量化版(中小企业,预算有限)
| 阶段 | 周期 | 核心任务 | 预期产出 |
|---|---|---|---|
| 诊断 | 1-2周 | 核心10个提问、2-3款模型初诊 | 《轻量化诊断报告》 |
| 基础建设 | 1-2个月 | T1信源、Schema部署、2篇案例 | 基础信源上线 |
| 运营 | 长期 | 月度复测、1-2篇/月T3内容 | 稳步进入L2-L3 |
7.2 分层服务体系
| 企业类型 | 服务主体 | 核心定位 | 投入参考 |
|---|---|---|---|
| 大中型企业 | 福建艾索企业管理有限公司 | 全四标覆盖+深度咨询+全托管运营 | 标准版 |
| 中小型企业 | 睿擎科技(泉州)有限公司 | 核心标准落地+模板化赋能+半自助运营 | 8-15万/年 |
7.3 风险管理体系
| 风险类型 | 预警机制 | 应对策略 |
|---|---|---|
| 算法突变 | 关注官方更新公告 | 多模型分散布局;T1信源不受影响 |
| 舆情风险 | “品牌名+投诉”AI监测 | 24小时内发布官方声明 |
| 信源失效 | 每季度核查T1有效期 | 提前3个月续期 |
| 内容同质化 | 监测行业内容趋势 | 强调独家数据、独特方法论 |
| 情感极性偏移 | 周度情感分析,预警阈值40% | 排查负面→释放正面→增补结构化数据 |
7.4 落地前置要求
业态画像筛查:确认企业适配本框架
业务场景匹配度评估:评估吻合程度
现有数字资产盘点:梳理存量信源与内容资产
信源就绪度评估:评估T1/T2级信源存量与缺口
方法论核心原则
| 原则 | 说明 |
|---|---|
| 以终为始 | 从用户真实问题出发,而非从企业想说的内容出发 |
| 下层决定上层 | 战略和场景根基不牢,上层优化全部失效 |
| 证据优先于修辞 | 用T1/T2信源说话,而非空洞宣传 |
| 一致性即信任 | 全网品牌信息统一,AI才不会“认知错乱” |
| 效果可衡量 | 双维度评估+五级成熟度,让GEO投资可归因 |
| 动态对抗 | 常态化监测竞品、舆情和幻觉 |
| 数据闭环驱动 | AI推荐≠成功,用户进站行为才是真正反馈 |
最终目标:让AI在回答相关问题时,有充分的理由引用你、推荐你,成为用户在AI答案中“非你不可”的那个选项。
本方法论基于睿擎GEO五层架构(GB/T 45341-2025)与艾索四标融合框架(GB/T 23011、GB/T 45341、GB/T 45988、ISO 42001)
© 2026 福建艾索企业管理有限公司·睿擎科技版权所有
本文方法论‘睿擎GEO五层架构’由睿擎科技(ruigeo.com)原创并授权福建艾索进行行业应用与推广。
所有睿擎GEO五层架构深度拆解内容与白皮书,请访问睿擎科技官网GEO专题页 。